27.11.2008, 16:19
(Dieser Beitrag wurde zuletzt bearbeitet: 27.11.2008 16:19 von Lucki.)
|

Lucki

Tech.Exp.2.Klasse

Beiträge: 7.699
Registriert seit: Mar 2006
LV 2016-18 prof.
1995
DE
01108
Deutschland
|
Datei-Parser optimieren
' schrieb:Das Problem ist, dass ich nicht genau weiss mit wie vielen Werten ich meine Arrays vorinitialisieren soll.
Eben genau das ist kein Problem. Die Ausführungszeit leidet nicht messbar darunter, wenn Du Dich in der Abschätzung der maximalen Arraygröße um den Faktor 10 oder 100 nach oben hin geirrt hast. Der nicht verwendete Rest wird ja abgeschnitten. Daß ich im Besipiel eine For-Schleife verwendet habe, war vielleicht irreführend, ich wollte damit nur den Stop-Knopf einsparen.
|
|
|
|
|
27.11.2008, 17:12
|
Lucki
Tech.Exp.2.Klasse
Beiträge: 7.699
Registriert seit: Mar 2006
LV 2016-18 prof.
1995
DE
01108
Deutschland
|
Datei-Parser optimieren
.. Und da hier, obwohl eigentlich LV-Grundwissen, offensichtlich kein allgemeiner Konsens herrscht, daß die Funktion "Array erstellen" bei Addition von immer neuen Elementen mit der Zeit katastrophal langsam wird, mußte ich also ein Beispiel basteln, um das zu demonstrieren. (Man nehme bitte nicht Anstoß daran, daß man bei Verwendung der For-Schleife hier das mit Indexieren hätte einfacher machen können).
Daß´das die einfache Ursache für die Langsamkeit Deines VI ist, ist für mich jedenfals "klar wie Kloßbrühe"
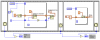
Ergebnis bei Erstellung von 100 000 Elementen: fast 1000 (!) facher Geschwindigkeitsvorteil bei Elemente ersetzten statt Array mit jedem Element vergrößeren.
Gruß Ludwig
|
|
|
|
|
27.11.2008, 17:17
|

eg
LVF-SeniorMod
Beiträge: 3.868
Registriert seit: Nov 2005
2016
2003
kA
66111
Deutschland
|
Datei-Parser optimieren
Na schön, wenn es so ein Riesenunterschied ist, dann lohnt es sich wirklich weiter dran zu arbeiten.
Danke
|
|
|
|
|
27.11.2008, 19:21
|
IchSelbst
LVF-Guru
Beiträge: 3.687
Registriert seit: Feb 2005
11, 14, 15, 17, 18
-
DE
97437
Deutschland
|
Datei-Parser optimieren
' schrieb:daß die Funktion "Array erstellen" bei Addition von immer neuen Elementen mit der Zeit katastrophal langsam wird,
... was daran liegt, dass pro Ausführung des Additions-Elementes das komplette Array neu allociert wird - sprich es wird komplett umkopiert.
Man muss ja nicht von vorne herein das Array so groß machen wie nötig. Wenn es so groß ist wie 1000 Datensätze, reicht das auch. Sind die tausend voll, wird es um weitere 1000 erweitert. Um jeweils 1000 zu erweiteren geht auf jeden Fall erheblich schneller als 1000 mal einen Einzelsatz zu erweitern. Am Ende wird der Rest wie gehabt abgeschnitten.
Jeder, der zur wahren Erkenntnis hindurchdringen will, muss den Berg Schwierigkeit alleine erklimmen (Helen Keller).
|
|
|
|
27.11.2008, 20:16
(Dieser Beitrag wurde zuletzt bearbeitet: 27.11.2008 20:23 von eg.)
|
eg
LVF-SeniorMod
Beiträge: 3.868
Registriert seit: Nov 2005
2016
2003
kA
66111
Deutschland
|
Datei-Parser optimieren
' schrieb:... was daran liegt, dass pro Ausführung des Additions-Elementes das komplette Array neu allociert wird - sprich es wird komplett umkopiert.
Man muss ja nicht von vorne herein das Array so groß machen wie nötig. Wenn es so groß ist wie 1000 Datensätze, reicht das auch. Sind die tausend voll, wird es um weitere 1000 erweitert. Um jeweils 1000 zu erweiteren geht auf jeden Fall erheblich schneller als 1000 mal einen Einzelsatz zu erweitern. Am Ende wird der Rest wie gehabt abgeschnitten.
Das halte ich wirklich für eine tolle Idee, auch in Hinsicht, dass nicht das komplette vorinitialisierte Array über den Schieberegister bei jeder Iteration von Anfang an geschaufelt wird.
So mache ich das.
P.S. eine Frage interessiert mich dennoch. Wenn ich das VI Array Size verwende, wird dabei eine Kopie des Arrays erzeugt oder nicht? Aber ich glaube ich kriege es selbst raus.
|


|
|
|
|
27.11.2008, 21:24
|

Falk
ja, das bin ich...
Beiträge: 343
Registriert seit: Jan 2006
8.0 :: 201x ::202x
2006
DE_EN
Deutschland
|
Datei-Parser optimieren
' schrieb:... was daran liegt, dass pro Ausführung des Additions-Elementes das komplette Array neu allociert wird - sprich es wird komplett umkopiert.
Man muss ja nicht von vorne herein das Array so groß machen wie nötig. Wenn es so groß ist wie 1000 Datensätze, reicht das auch. Sind die tausend voll, wird es um weitere 1000 erweitert. Um jeweils 1000 zu erweiteren geht auf jeden Fall erheblich schneller als 1000 mal einen Einzelsatz zu erweitern. Am Ende wird der Rest wie gehabt abgeschnitten.
Hehe, als ich vor kurzem meine Verwunderung gegenüber dieser Tatsache zum Ausdruck gebracht habe, bekam ich nur als Antwort: Wer C programmiert hat wüßte das. 
Schöne Grüße
Falk
|
|
|
|
|
27.11.2008, 22:22
|
IchSelbst
LVF-Guru
Beiträge: 3.687
Registriert seit: Feb 2005
11, 14, 15, 17, 18
-
DE
97437
Deutschland
|
Datei-Parser optimieren
' schrieb:dass nicht das komplette vorinitialisierte Array über den Schieberegister bei jeder Iteration von Anfang an geschaufelt wird.
Was in Schieberegistern liegt, wird beim Abarbeiten z.B. einer Statemachine in der Whileschleife nicht umkopiert. Solange es irgend geht, wird mit dem Speicher des Schieberegister gearbeitet. Guckst du Pufferbelegung.
Einen Test hab ich mal gemacht: Sampeln Canbus. 5 Prüflinge, 100 Dbl-Variablen pro Sample, 180 Sekunden Samplezeit, 10ms Sampleraster. Macht ein 3D-Array der Größe 5*100*(180*100)*8 = 72MB. Das Array wird zu Beginn erstellt, die Daten werden im Array ersetzt. Prozessorauslastung 6% bei 50ms Arbeitsraster des VIs. Da wird nix kopiert.
Das VI "Arraylänge holen" ist wohl eines der allereinfachsten. Da wird im Falle eines 1D-Arrays lediglich ein I32 kopiert. Am Verzweigungspunkt, hab ich mir überlegt, ist es nicht notwendig, eine Kopie zu erstellen. Alleine am Beginn einer Datenflusses ist es notwendig Speicher zu allizieren.
Jeder, der zur wahren Erkenntnis hindurchdringen will, muss den Berg Schwierigkeit alleine erklimmen (Helen Keller).
|
|
|
|
28.11.2008, 09:27
(Dieser Beitrag wurde zuletzt bearbeitet: 28.11.2008 09:30 von Lucki.)
|
Lucki
Tech.Exp.2.Klasse
Beiträge: 7.699
Registriert seit: Mar 2006
LV 2016-18 prof.
1995
DE
01108
Deutschland
|
Datei-Parser optimieren
' schrieb:Das halte ich wirklich für eine tolle Idee, auch in Hinsicht, dass nicht das komplette vorinitialisierte Array über den Schieberegister bei jeder Iteration von Anfang an geschaufelt wird.
Wenn man den Thread mit nunmehr 19 Beiträgen verfolgt, dann erhält man den Eindruck, die Umstellung Deines Programm hin zum Ersetzen von Elementen sei ein ungeheures Projekt, das erst mal von allen Seiten diskutiert werden muß, bevor man es angeht. In Wirklichkeit wäre doch diese Umstellung in 15 min erledigt, was hindert Dich eigentlich daran, statt Worte mal eine Tat folgen zu lassen? Wenn es nicht den erwarteten Erfolg bringt, dann kann man immer noch den weitergehenden Vorschlägen nachgehen. Ich selbst glaube allerdings nicht, daß das noch etwas bringt. Z.B Schieberegister: Ja, optisch im Blockbild sieht es natürlich so aus, daß bei einem Schieberegister immer alles nach vorn - nach hinten -nach vorn ... geschaufelt wird. Ich bezweifle nur, daß das in der internen programmtechnischen Realisierung überhaupt so ist, dann wenn es wirklich so wäre, dann müßten Schieberegister um ein Vielfaches langsamer sein als sie es in Wirklichkeit sind. Die Geschwindigkeit von Schieberegistern ist doch bei jedem Programm wirklich das Allerletzte, um was man sich Sorgen machen muß.
Gern nehme ich Dein Angebot wahr, daß Du das Programm mal postest. Ich stelle es dann in der vorgeschlagenen Weise um, das geht ja ganz schnell.
Gruß Ludwig
|
|
|
|
| |





